---
title: "Introduction to survatr"
code-fold: show
code-tools: true
vignette: >
%\VignetteIndexEntry{Introduction to survatr}
%\VignetteEngine{quarto::html}
%\VignetteEncoding{UTF-8}
bibliography: references.bib
---
```{r}
#| include: false
knitr::opts_chunk$set(collapse = TRUE, comment = "#>")
set.seed(2026)
```
survatr extends the [causatr](https://github.com/etverse/causatr) engine
to **time-to-event outcomes**, following the causal survival analysis of
@hernan_whatif, Ch. 17, via three building blocks:
- **Pooled-logistic hazard g-computation** on person-period data:
$\text{logit}\, h(t \mid A, L) = \alpha(t) + \beta_A A + \beta_L L$, with
survival cumulated across periods as
$\hat{S}^a_i(t) = \prod_{k \leq t}(1 - \hat{h}^a_{i,k})$. For small
per-period hazards this discrete-time model approximates time-dependent
Cox regression closely [@dagostino1990pooled].
- **Delta-method sandwich variance** that propagates per-row influence
functions through the cumulative product into a cross-time covariance
matrix on the survival curve.
- **Individual-level nonparametric bootstrap** that resamples ids (all of
each id's person-period rows together) and refits the hazard model per
replicate.
The **estimand is a curve** (survival, risk, RMST) or a contrast of
curves (risk difference, risk ratio, RMST difference), not a scalar. The
entire API returns time-indexed `data.table`s.
## Two-step API
All analyses follow the same two-step pattern that `causatr` users will
recognise:
```r
# Step 1: Fit the hazard model once
fit <- surv_fit(
data,
outcome = "Y",
treatment = "A",
confounders = ~ L1 + L2,
id = "id",
time = "t",
censoring = "C",
time_formula = ~ splines::ns(t, 4) # alpha(t) baseline hazard
)
# Step 2: Contrast many interventions cheaply on the same fit
result <- contrast(
fit,
interventions = list(
treated = causatr::static(1),
control = causatr::static(0)
),
times = seq(0, 120, by = 12),
type = "risk_difference",
reference = "control",
ci_method = "sandwich"
)
```
## Quick example
The example below uses a simulated DGP: a constant discrete-time hazard
of 6% per period, a single binary treatment with no causal effect, and
one normal-distributed confounder that jointly affects the propensity of
treatment and the hazard rate. Under this DGP the counterfactual
survival under either intervention converges to $(1 - 0.06)^t$, so we
can check the point estimates against the closed form.
```{r}
#| message: false
## Attach `causatr` first so survatr's `contrast()` generic shadows
## causatr's scalar-outcome `contrast()` and dispatches correctly on
## `survatr_fit` objects. Call `causatr::contrast()` explicitly if you
## need the causatr path while survatr is loaded.
library(causatr)
library(survatr)
library(data.table)
## Simulate person-period data with a constant hazard and a confounder L.
sim_pp <- function(n = 1500L, K = 10L, h = 0.06, seed = 1L) {
set.seed(seed)
L <- rnorm(n) # single baseline confounder
A <- rbinom(n, 1L, plogis(0.3 * L)) # L affects treatment
rows <- vector("list", n)
for (i in seq_len(n)) {
Y <- rbinom(K, 1L, h) # hazard independent of A (null)
first <- which(Y == 1L)[1L]
if (!is.na(first) && first < K) Y[(first + 1L):K] <- 0L
rows[[i]] <- data.table::data.table(
id = i, t = seq_len(K), A = A[i], L = L[i], Y = Y
)
}
data.table::rbindlist(rows)
}
pp <- sim_pp()
head(pp, 5)
```
### Fit the hazard model
```{r}
fit <- surv_fit(
pp,
outcome = "Y",
treatment = "A",
confounders = ~ L,
id = "id",
time = "t",
time_formula = ~ factor(t) # non-parametric baseline hazard
)
fit
```
### Survival curves under two interventions
```{r}
res_surv <- contrast(
fit,
interventions = list(
a1 = causatr::static(1),
a0 = causatr::static(0)
),
times = 1:10,
type = "survival",
ci_method = "sandwich"
)
res_surv
```
```{r}
#| fig-width: 7
#| fig-height: 4
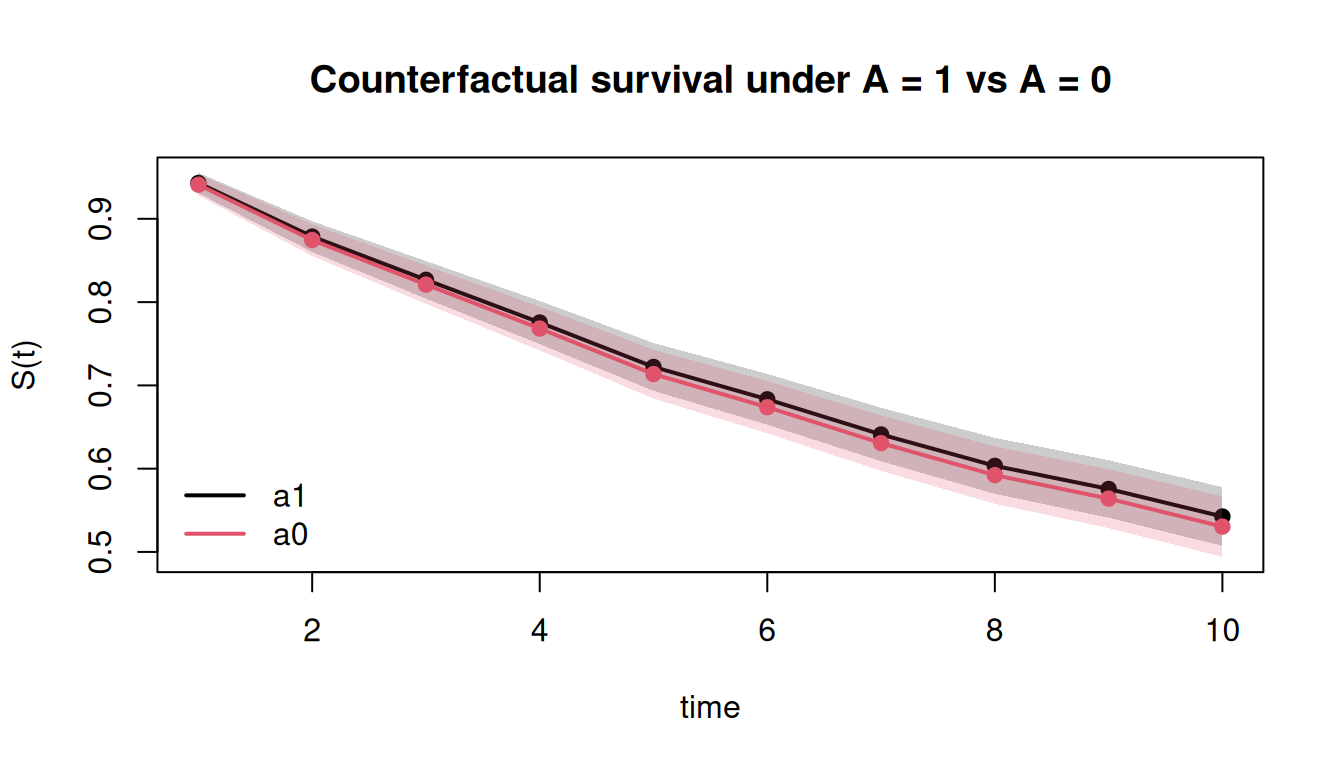
plot(res_surv, main = "Counterfactual survival under A = 1 vs A = 0")
```
### Risk difference with sandwich CI
```{r}
res_rd <- contrast(
fit,
interventions = list(
a1 = causatr::static(1),
a0 = causatr::static(0)
),
times = 1:10,
type = "risk_difference",
reference = "a0",
ci_method = "sandwich"
)
res_rd$contrasts[] # `[]` forces auto-print of a function-returned data.table
```
```{r}
#| fig-width: 7
#| fig-height: 4
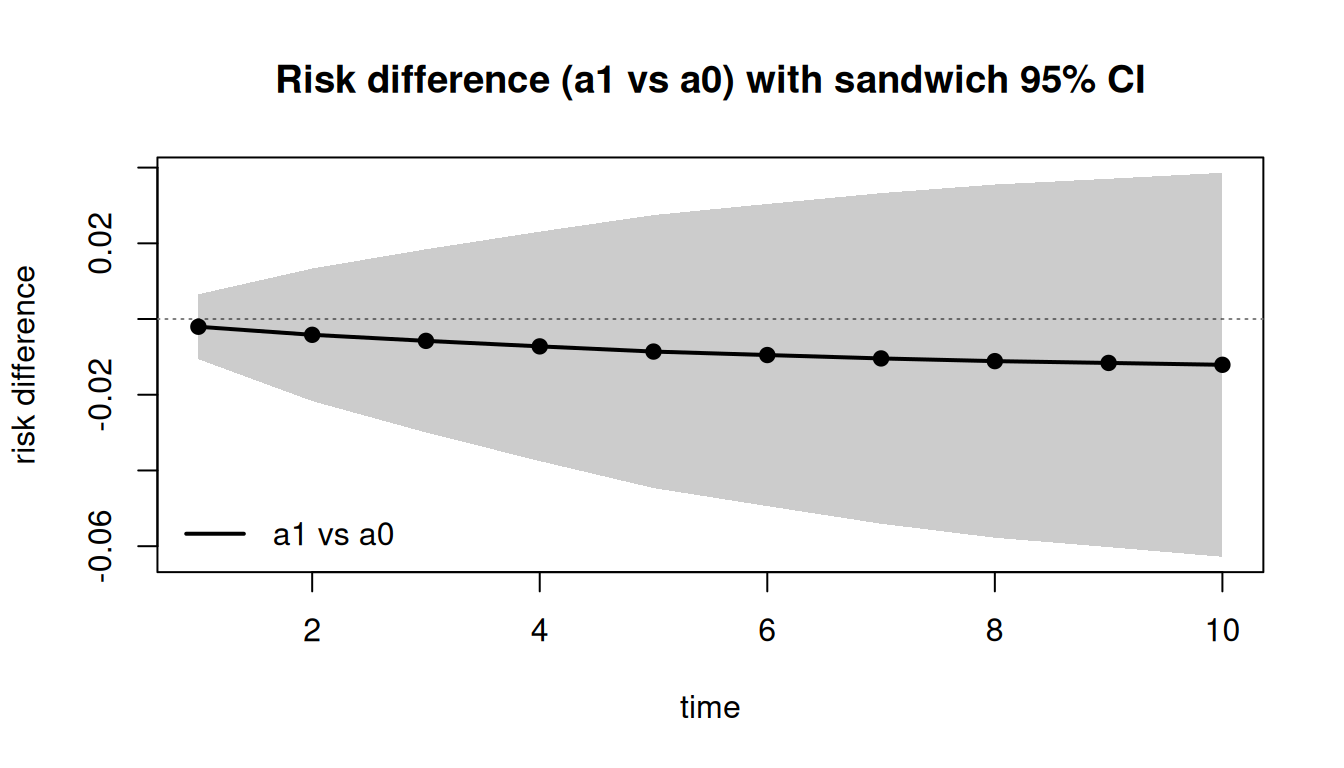
plot(res_rd, main = "Risk difference (a1 vs a0) with sandwich 95% CI")
```
The DGP has no treatment effect, so the risk-difference CI should
comfortably cover 0 at every time point.
## Estimand menu
Pass any of the following to `type =`:
| `type` | Estimand | Shape of result |
|---|---|---|
| `"survival"` | $\hat{S}^a(t)$ | One row per (intervention, time) |
| `"risk"` | $1 - \hat{S}^a(t)$ | One row per (intervention, time) |
| `"rmst"` | $\int_0^t \hat{S}^a(u)\,du$ | One row per (intervention, time) |
| `"risk_difference"` | $\hat{R}^{a_1}(t) - \hat{R}^{a_0}(t)$ | Pairwise contrasts |
| `"risk_ratio"` | $\hat{R}^{a_1}(t) / \hat{R}^{a_0}(t)$ | Pairwise contrasts (log-scale CI) |
| `"rmst_difference"` | $\mathrm{RMST}^{a_1}(t) - \mathrm{RMST}^{a_0}(t)$ | Pairwise contrasts |
`"survival"`, `"risk"`, and `"rmst"` return an **empty contrasts table**
(stable schema); the three pairwise types fill it.
## Intervention types
Interventions are constructed via `causatr`:
| Constructor | Description | Example |
|---|---|---|
| `causatr::static(value)` | Set treatment to a fixed value | `static(1)` |
| `causatr::shift(delta)` | Add a constant to observed treatment | `shift(0.5)` |
| `causatr::scale_by(factor)` | Multiply observed treatment | `scale_by(0.5)` |
| `causatr::threshold(lower, upper)` | Clamp treatment within bounds | `threshold(0, 20)` |
| `causatr::dynamic(rule)` | Apply a user-defined rule | `dynamic(\(d, a) ifelse(d$L > 0, 1, 0))` |
The `dynamic()` rule and IPW (`estimator = "ipw"`) are demonstrated in
`vignette("ipw")`; longitudinal time-varying treatments via the
longitudinal ICE-hazard engine (`estimator = "ice"`) are covered in
`vignette("ice")`. IPW-style
stochastic (`ipsi()`) interventions ship in a later chunk.
## Inference methods
| `ci_method` | Description |
|---|---|
| `"none"` | Point estimates only (default). `se` / `ci_*` columns are `NA_real_`. |
| `"sandwich"` | Delta-method cross-time influence function aggregation through the cumulative product. Pointwise Wald bands. Fast (single pass). |
| `"bootstrap"` | Nonparametric bootstrap with per-id resampling. Percentile (default) or Wald CIs. Slower; required for non-GLM outcome fitters (e.g. `mgcv::gam`). |
```{r}
#| eval: true
res_boot <- contrast(
fit,
interventions = list(
a1 = causatr::static(1),
a0 = causatr::static(0)
),
times = 1:10,
type = "risk_difference",
reference = "a0",
ci_method = "bootstrap",
n_boot = 200L,
seed = 42L
)
head(res_boot$contrasts, 3)
```
Sandwich and bootstrap SEs match each other — and the true sampling SD
— to within 1–2% on this DGP at n = 1500 (confirmed via a 300-replicate
empirical-SD oracle; see `tests/testthat/test-bootstrap-survival.R`).
## Extracting results
`tidy()`, `plot()`, `print()`, and `forrest()` all dispatch on the
time-indexed `survatr_result` shape:
```{r}
res_td <- tidy(res_rd)
head(res_td, 6)
```
```{r}
#| fig-width: 7
#| fig-height: 3
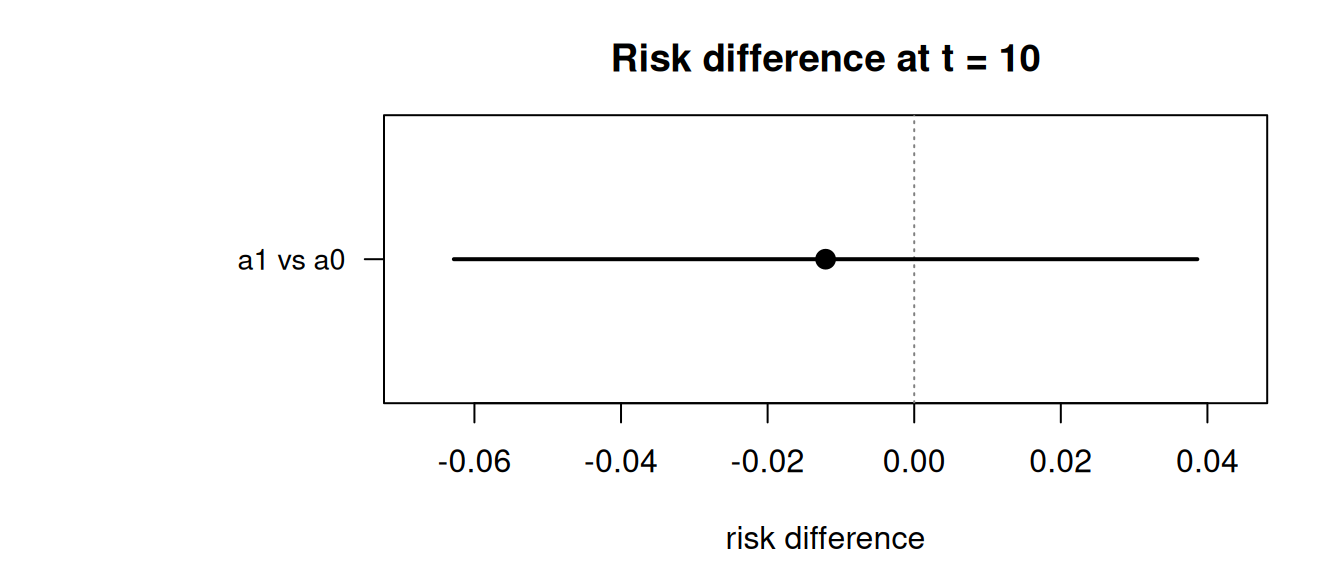
forrest(res_rd, t_ref = 10, main = "Risk difference at t = 10")
```
## Model diagnostics
`diagnose()` returns a `survatr_diag` with five panels that operate on the
same at-risk rows the hazard model was fit on:
```{r}
dx <- diagnose(fit)
print(dx)
```
The panels are accessible as plain `data.table`s:
```{r}
## Per-period hazard distribution: h_min / h_mean / h_max, flag_low / flag_high
dx$positivity
## Standardized mean differences (or cor(A, L) for continuous A)
dx$balance
```
`$weights` is non-`NULL` for IPW fits and holds the per-id ESS, maximum
weight, and top-5%-share. `$censoring` is populated when a `censoring`
column was supplied and reports per-arm censoring incidence (denominator is
the full person-period row count, `n_pp_rows`). `$competing` appears for
competing-risks fits and includes the partition-of-unity identity check.
## Reserved columns and error surface
survatr reserves column names prefixed with `.survatr_*` for internal
bookkeeping (`.survatr_prev_event`, `.survatr_prev_cens`). User-data
collisions produce `survatr_reserved_col`.
All rejection paths raise **classed** errors with the `survatr_*` prefix
so downstream code can pattern-match on class rather than English:
| Class | Trigger |
|---|---|
| `survatr_bad_interventions` | Empty / unnamed / duplicate-named / wrong-type `interventions`, or a pairwise-contrast `type` with a single intervention |
| `survatr_bad_times` | Non-numeric / empty / NA `times` |
| `survatr_time_extrapolation` | `times` outside `fit$time_grid` |
| `survatr_bad_reference` | `reference` not in `interventions` names |
| `survatr_bad_ci_method` | `ci_method` not in `{"none", "sandwich", "bootstrap"}` |
| `survatr_bad_conf_level` | `conf_level` outside `(0, 1)` |
| `survatr_bad_n_boot` / `survatr_bad_boot_ci` / `survatr_bad_parallel` | Bootstrap argument misuse |
| `survatr_matching_rejected` | `estimator = "matching"` (use `survival::coxph(..., weights, cluster)` instead) |
| `survatr_bad_na_action` | `na.action = na.exclude` (silently corrupts sandwich variance) |
| `survatr_competing_misuse` | Non-`NULL` `competing` argument (cause-specific path ships later) |
## Learning more
This vignette covered point-treatment g-computation. Two further estimators
are implemented and have dedicated vignettes:
- **Point-treatment IPW** (`vignette("ipw")`) — stabilized density-ratio
weights broadcast onto person-period rows, fitting a weighted marginal
hazard MSM.
- **Longitudinal ICE-hazard** (`vignette("ice")`) — longitudinal survival
for a time-varying treatment via iterated conditional expectations
[@zivich2024ice], with the hazard indicator at the final period and
a survival-tail pseudo-outcome at earlier periods.
survatr's full scope is laid out in `SURVIVAL_PACKAGE_HANDOFF.md`. v1 is now
complete (chunks 1–10). v1.x will add:
- **IPCW** — per-period cumulative censoring weights wired into the hazard MSM.
- **Extended estimands** — survival quantiles / median, RMTL, per-cause
years-of-life-lost.
- **Cluster-robust sandwich** — `cluster=` IF aggregation.
- **Left-truncation / delayed entry.**
## References
::: {#refs}
:::