---
title: "Diagnostics with causatr"
code-fold: show
code-tools: true
vignette: >
%\VignetteIndexEntry{Diagnostics with causatr}
%\VignetteEngine{quarto::html}
%\VignetteEncoding{UTF-8}
---
```{r}
#| include: false
knitr::opts_chunk$set(collapse = TRUE, comment = "#>")
```
`diagnose()` is causatr's diagnostic entry point. It produces positivity
summaries, covariate balance tables, and weight-distribution statistics
appropriate to the estimator and treatment type. This vignette walks
through every supported diagnostic scenario.
## Setup
```{r}
#| message: false
library(causatr)
data("nhefs")
nhefs_complete <- nhefs[
!is.na(nhefs$wt82_71) & !is.na(nhefs$education),
]
nhefs_complete$gained_weight <- as.integer(
nhefs_complete$wt82_71 > 0
)
nhefs_complete$sex <- factor(
nhefs_complete$sex,
levels = 0:1,
labels = c("Male", "Female")
)
```
## Basic usage: binary IPW
The simplest call takes a `causatr_fit` and returns a `causatr_diag`
object with positivity, balance, and weight-distribution panels. When
per-component confounders are used (e.g. `confounders_treatment`),
diagnostics automatically use the treatment-model confounders for
balance and positivity checks:
```{r}
fit_ipw <- causat(
nhefs_complete,
outcome = "wt82_71",
treatment = "qsmk",
confounders = ~ sex + age + race + education +
smokeintensity + smokeyrs + exercise + active + wt71,
estimator = "ipw",
model_fn = stats::glm,
propensity_model_fn = stats::glm
)
diag <- diagnose(fit_ipw)
diag
```
### Positivity
The positivity table reports propensity-score quantiles and the number
of observations near the boundaries (potential positivity violations):
```{r}
diag$positivity
```
### Covariate balance
The balance object comes from `cobalt::bal.tab()` and reports
standardised mean differences (SMD) and variance ratios:
```{r}
diag$balance
```
### Weight distribution
The weight table shows per-arm summary statistics and the effective
sample size (ESS). A large drop from the nominal $n$ to the ESS
indicates that a few individuals carry disproportionate weight:
```{r}
diag$weights
```
When extreme weights are detected, `contrast(trim = )` can winsorize
density-ratio weights at a specified quantile (e.g. `trim = 0.999`).
See `vignette("ipw")` for details.
## Per-intervention diagnostics
By default, `diagnose(fit)` produces a single `obs` panel using the
observed-treatment Horvitz--Thompson view. When you pass
`interventions =`, each intervention gets its own panel with
intervention-specific density-ratio weights:
```{r}
diag_iv <- diagnose(
fit_ipw,
interventions = list(
a1 = static(1),
a0 = static(0)
)
)
diag_iv
```
The per-intervention panels share the same positivity and balance
(both are properties of the fitted treatment model, not the
intervention), but the weight distribution differs because the
density-ratio weight $f(d(A)|L) / f(A|L)$ depends on $d$.
## Plot methods
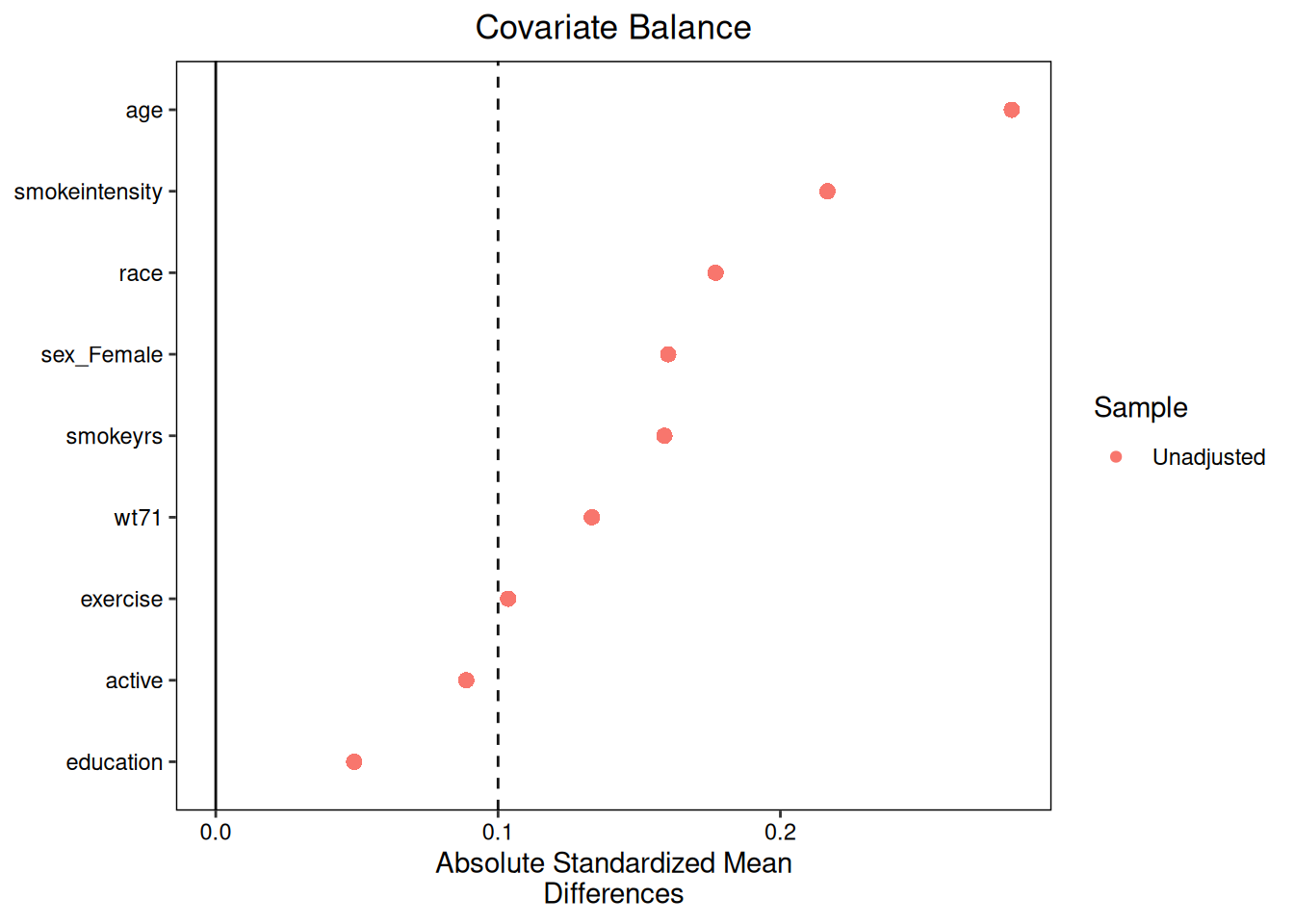
### Love plot (balance)
The default `plot(diag)` produces a Love plot via `cobalt::love.plot()`.
Covariates with absolute SMD below the threshold (dashed line at 0.1)
are well-balanced:
```{r}
#| fig-width: 7
#| fig-height: 5
#| fig-alt: "Love plot showing covariate balance."
#| eval: !expr requireNamespace("cobalt", quietly = TRUE)
plot(diag)
```
### Weight distribution
```{r}
#| fig-width: 7
#| fig-height: 4
#| fig-alt: "Histogram of IPW weights by treatment arm."
#| eval: !expr requireNamespace("tinyplot", quietly = TRUE)
plot(diag, which = "weights")
```
Log-scale can help when weights have a long right tail:
```{r}
#| fig-width: 7
#| fig-height: 4
#| fig-alt: "Log-scale histogram of IPW weights by treatment arm."
#| eval: !expr requireNamespace("tinyplot", quietly = TRUE)
plot(diag, which = "weights", log_scale = TRUE)
```
### Propensity-score distribution
```{r}
#| fig-width: 7
#| fig-height: 4
#| fig-alt: "Propensity score density by treatment arm."
#| eval: !expr requireNamespace("tinyplot", quietly = TRUE)
plot(diag, which = "positivity")
```
## Estimand-specific diagnostics: ATT / ATC
Under ATT, the treated group gets unit weights (all exactly 1) and
the control group is reweighted by $p/(1-p)$ to match the treated
covariate distribution:
```{r}
fit_att <- causat(
nhefs_complete,
outcome = "wt82_71",
treatment = "qsmk",
confounders = ~ sex + age + race + education +
smokeintensity + smokeyrs + exercise + active + wt71,
estimator = "ipw",
estimand = "ATT",
model_fn = stats::glm,
propensity_model_fn = stats::glm
)
diag_att <- diagnose(fit_att)
diag_att$weights
```
Under ATC, the roles reverse: controls get unit weights, treated are
reweighted by $(1-p)/p$:
```{r}
fit_atc <- causat(
nhefs_complete,
outcome = "wt82_71",
treatment = "qsmk",
confounders = ~ sex + age + race + education +
smokeintensity + smokeyrs + exercise + active + wt71,
estimator = "ipw",
estimand = "ATC",
model_fn = stats::glm,
propensity_model_fn = stats::glm
)
diag_atc <- diagnose(fit_atc)
diag_atc$weights
```
## Stratified balance with `by =`
When effect modification is present, `by =` reports covariate balance
within each stratum of the modifier variable:
```{r}
diag_by <- diagnose(fit_ipw, by = "sex")
diag_by$balance
```
## G-computation diagnostics
G-computation has no weights or treatment model, so `diagnose()`
reports unadjusted covariate balance only --- useful for assessing
how much the observational study relies on model extrapolation:
```{r}
fit_gcomp <- causat(
nhefs_complete,
outcome = "wt82_71",
treatment = "qsmk",
confounders = ~ sex + age + race + education +
smokeintensity + smokeyrs + exercise + active + wt71,
estimator = "gcomp",
model_fn = stats::glm
)
diag_gcomp <- diagnose(fit_gcomp)
diag_gcomp
```
## Matching diagnostics
Matching diagnostics include a match-quality summary (number matched /
discarded) plus covariate balance before and after matching:
```{r}
fit_m <- causat(
nhefs_complete,
outcome = "wt82_71",
treatment = "qsmk",
confounders = ~ sex + age + race + education +
smokeintensity + smokeyrs + exercise + active + wt71,
estimator = "matching"
)
diag_m <- diagnose(fit_m)
diag_m
```
## Continuous treatment
For continuous treatments, positivity is assessed via the conditional
density $f(A_i \mid L_i)$ rather than a propensity score. Observations
with very low density are flagged as potential positivity violations:
```{r}
fit_cont <- causat(
nhefs_complete,
outcome = "wt82_71",
treatment = "smokeintensity",
confounders = ~ sex + age + race + education +
smokeyrs + exercise + active + wt71,
estimator = "ipw",
model_fn = stats::glm,
propensity_model_fn = stats::glm
)
diag_cont <- diagnose(fit_cont)
diag_cont$positivity
```
With a shift intervention, the weight distribution shows the density
ratio under the shifted treatment:
```{r}
diag_cont_shift <- diagnose(
fit_cont,
interventions = list(
shift_down = shift(-5)
)
)
diag_cont_shift$per_intervention$shift_down$weights
```
## Categorical treatment
Categorical treatments (>2 levels) report per-level probability
summaries: $P(A = k \mid L)$ quantiles for each treatment level:
```{r}
nhefs_complete$exercise_cat <- factor(
nhefs_complete$exercise,
levels = 0:2,
labels = c("low", "moderate", "high")
)
fit_cat <- causat(
nhefs_complete,
outcome = "wt82_71",
treatment = "exercise_cat",
confounders = ~ sex + age + race + smokeintensity + wt71,
estimator = "ipw",
model_fn = stats::glm,
propensity_model_fn = nnet::multinom
)
diag_cat <- diagnose(fit_cat)
diag_cat$positivity
```
## Longitudinal diagnostics
Longitudinal fits (ICE or longitudinal IPW) produce per-period
diagnostic panels. Each time point gets its own positivity, balance,
and weight summary:
```{r}
set.seed(42)
n <- 200
dt_long <- data.table::data.table(
id = rep(1:n, each = 3),
time = rep(0:2, n),
L = rnorm(n * 3),
A = rbinom(n * 3, 1, 0.5),
Y = rnorm(n * 3)
)
dt_long[, A := rbinom(.N, 1, plogis(0.5 * L))]
dt_long[, Y := 1 + 0.5 * A + 0.3 * L + rnorm(.N)]
fit_long <- causat(
dt_long,
outcome = "Y",
treatment = "A",
confounders = ~ L,
id = "id",
time = "time",
estimator = "ipw",
model_fn = stats::glm,
propensity_model_fn = stats::glm
)
diag_long <- diagnose(fit_long)
diag_long
```
The positivity and weights are stored as named lists keyed by
time-point string. The cumulative product weight (across all periods)
is stored under the `"cumulative"` key:
```{r}
names(diag_long$weights)
diag_long$weights[["cumulative"]]
```
## Summary
| Estimator | Positivity | Balance | Weights |
|---|---|---|---|
| IPW (binary) | PS quantiles + violation counts | cobalt SMDs | Per-arm HT weights + ESS |
| IPW (continuous) | Density quantiles + low-density count | Correlations | Overall density-ratio weights |
| IPW (categorical) | Per-level P(A=k\|L) quantiles | cobalt pairwise SMDs | Overall weights |
| IPW (count) | Density quantiles | Correlations | Overall weights |
| IPW (multivariate) | Per-component positivity | First-component SMDs | Combined product weights |
| Matching | PS quantiles | cobalt before/after | Match quality |
| G-computation | PS quantiles | Unadjusted SMDs | --- |
| Longitudinal IPW | Per-period positivity | Per-period balance | Per-period + cumulative |
| Longitudinal ICE | --- | Per-period balance | --- |